
Update README.md
Browse files
README.md
CHANGED
|
@@ -11,4 +11,246 @@ license: mit
|
|
| 11 |
short_description: PyTorch CV models comparison.
|
| 12 |
---
|
| 13 |
|
| 14 |
-
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
| 11 |
short_description: PyTorch CV models comparison.
|
| 12 |
---
|
| 13 |
|
| 14 |
+
# PyTorch Model Comparison: From Custom CNNs to Advanced Transfer Learning
|
| 15 |
+
|
| 16 |
+

|
| 17 |
+

|
| 18 |
+

|
| 19 |
+

|
| 20 |
+

|
| 21 |
+
|
| 22 |
+
---
|
| 23 |
+
|
| 24 |
+
## Overview
|
| 25 |
+
|
| 26 |
+
This project compares **three computer vision approaches in PyTorch** on a vehicle classification task:
|
| 27 |
+
|
| 28 |
+
1. Custom CNN (trained from scratch)
|
| 29 |
+
2. Vision Transformer (DeiT-Tiny)
|
| 30 |
+
3. Xception with two-phase transfer learning
|
| 31 |
+
|
| 32 |
+
The goal is to answer a practical question:
|
| 33 |
+
|
| 34 |
+
> On small or moderately sized datasets, should you train from scratch or use transfer learning?
|
| 35 |
+
|
| 36 |
+
The results clearly show that **transfer learning dramatically improves generalization and reliability**, especially when data and compute are limited.
|
| 37 |
+
|
| 38 |
+
---
|
| 39 |
+
|
| 40 |
+
## Architectures Compared
|
| 41 |
+
|
| 42 |
+
### Custom CNN (From Scratch)
|
| 43 |
+
|
| 44 |
+
A traditional convolutional network built manually with Conv → ReLU → Pooling blocks and fully connected layers.
|
| 45 |
+
|
| 46 |
+
**Philosophy:** Full architectural control, no pre-training.
|
| 47 |
+
|
| 48 |
+
Minimal structure:
|
| 49 |
+
|
| 50 |
+
```python
|
| 51 |
+
class CustomCNN(nn.Module):
|
| 52 |
+
def __init__(self, num_classes):
|
| 53 |
+
super().__init__()
|
| 54 |
+
self.features = nn.Sequential(
|
| 55 |
+
nn.Conv2d(3, 32, 3, padding=1),
|
| 56 |
+
nn.ReLU(),
|
| 57 |
+
nn.MaxPool2d(2),
|
| 58 |
+
nn.Conv2d(32, 64, 3, padding=1),
|
| 59 |
+
nn.ReLU(),
|
| 60 |
+
nn.MaxPool2d(2)
|
| 61 |
+
)
|
| 62 |
+
self.classifier = nn.Sequential(
|
| 63 |
+
nn.Linear(64 * 56 * 56, 256),
|
| 64 |
+
nn.ReLU(),
|
| 65 |
+
nn.Dropout(0.5),
|
| 66 |
+
nn.Linear(256, num_classes)
|
| 67 |
+
)
|
| 68 |
+
```
|
| 69 |
+
|
| 70 |
+
**Reality on small datasets:**
|
| 71 |
+
|
| 72 |
+
* Slower convergence
|
| 73 |
+
* Higher variance
|
| 74 |
+
* Larger generalization gap
|
| 75 |
+
|
| 76 |
+
---
|
| 77 |
+
|
| 78 |
+
### Vision Transformer (DeiT-Tiny)
|
| 79 |
+
|
| 80 |
+
Using Hugging Face's pre-trained Vision Transformer:
|
| 81 |
+
|
| 82 |
+
```python
|
| 83 |
+
model = AutoModelForImageClassification.from_pretrained(
|
| 84 |
+
"facebook/deit-tiny-patch16-224",
|
| 85 |
+
num_labels=num_classes,
|
| 86 |
+
ignore_mismatched_sizes=True
|
| 87 |
+
)
|
| 88 |
+
```
|
| 89 |
+
|
| 90 |
+
Trained with the Hugging Face `Trainer` API.
|
| 91 |
+
|
| 92 |
+
**Advantages:**
|
| 93 |
+
|
| 94 |
+
* Stable convergence
|
| 95 |
+
* Lightweight
|
| 96 |
+
* Easy deployment
|
| 97 |
+
* Good performance-to-efficiency ratio
|
| 98 |
+
|
| 99 |
+
---
|
| 100 |
+
|
| 101 |
+
### Xception (Two-Phase Transfer Learning)
|
| 102 |
+
|
| 103 |
+
Implemented using `timm`.
|
| 104 |
+
|
| 105 |
+
### Phase 1 - Train Classifier Head Only
|
| 106 |
+
|
| 107 |
+
```python
|
| 108 |
+
model = timm.create_model("xception", pretrained=True)
|
| 109 |
+
|
| 110 |
+
for param in model.parameters():
|
| 111 |
+
param.requires_grad = False
|
| 112 |
+
|
| 113 |
+
model.fc = nn.Sequential(
|
| 114 |
+
nn.Linear(in_features, 512),
|
| 115 |
+
nn.ReLU(),
|
| 116 |
+
nn.Dropout(0.5),
|
| 117 |
+
nn.Linear(512, num_classes)
|
| 118 |
+
)
|
| 119 |
+
```
|
| 120 |
+
|
| 121 |
+
### Phase 2 - Fine-Tune Selected Layers
|
| 122 |
+
|
| 123 |
+
```python
|
| 124 |
+
for name, param in model.named_parameters():
|
| 125 |
+
if "block14" in name or "fc" in name:
|
| 126 |
+
param.requires_grad = True
|
| 127 |
+
```
|
| 128 |
+
|
| 129 |
+
Lower learning rate used during fine-tuning.
|
| 130 |
+
|
| 131 |
+
**Result:**
|
| 132 |
+
- Smoothest training curves
|
| 133 |
+
- Lowest validation loss
|
| 134 |
+
- Highest test accuracy
|
| 135 |
+
- Strongest performance on unseen internet images
|
| 136 |
+
|
| 137 |
+
---
|
| 138 |
+
|
| 139 |
+
## Comparative Results
|
| 140 |
+
|
| 141 |
+
| Model | Validation Performance | Generalization | Stability |
|
| 142 |
+
| ---------- | ---------------------- | -------------- | ----------- |
|
| 143 |
+
| Custom CNN | High variance | Weak | Unstable |
|
| 144 |
+
| DeiT-Tiny | Strong | Good | Stable |
|
| 145 |
+
| Xception | Best | Excellent | Very Stable |
|
| 146 |
+
|
| 147 |
+
### Key Insight
|
| 148 |
+
|
| 149 |
+
> High validation accuracy does NOT guarantee real-world reliability.
|
| 150 |
+
|
| 151 |
+
Custom CNN achieved strong validation scores (~87%) but struggled more on distribution shifts.
|
| 152 |
+
|
| 153 |
+
Xception consistently generalized better.
|
| 154 |
+
|
| 155 |
+
---
|
| 156 |
+
|
| 157 |
+
## Experimental Visualizations
|
| 158 |
+
|
| 159 |
+
### Dataset Distribution Across All Three Models:
|
| 160 |
+
|
| 161 |
+
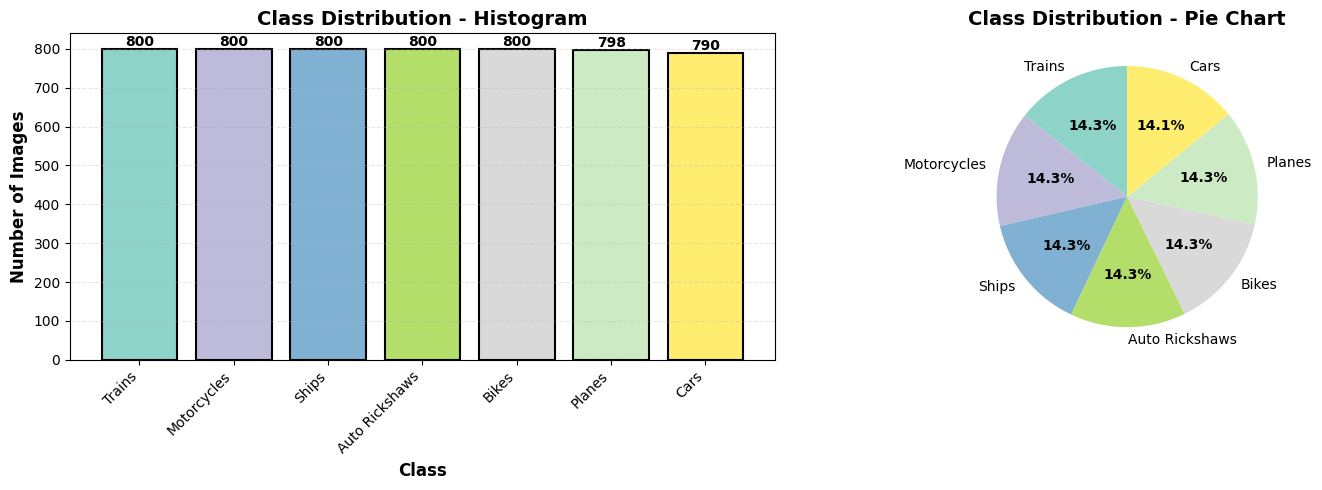
|
| 162 |
+
|
| 163 |
+
---
|
| 164 |
+
|
| 165 |
+
### Xception Model:
|
| 166 |
+
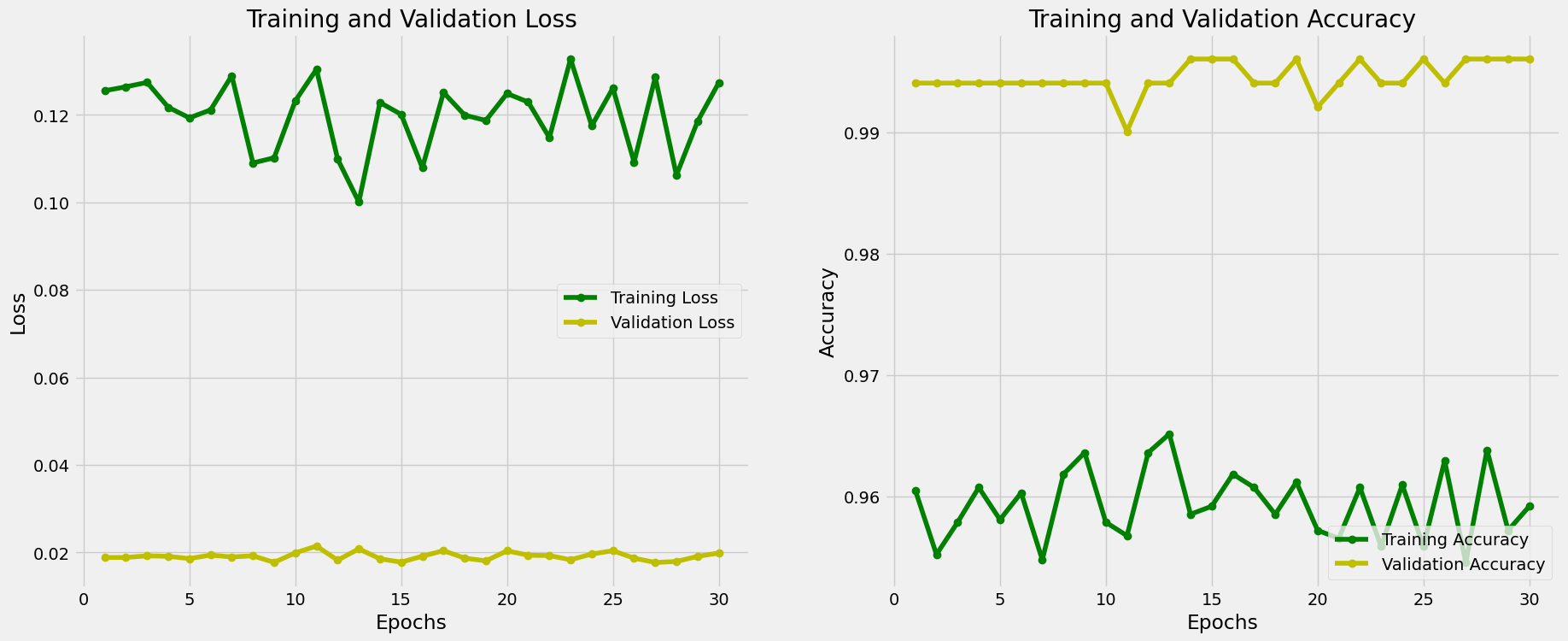
|
| 167 |
+
### Custom CNN Model:
|
| 168 |
+
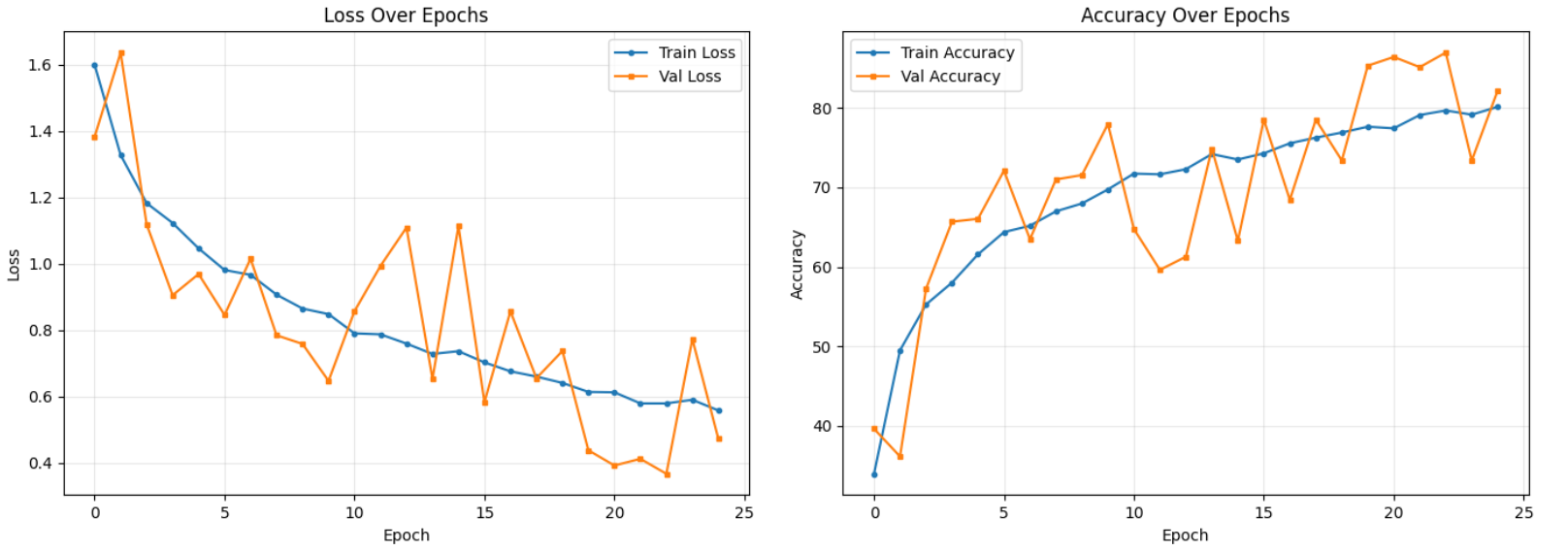
|
| 169 |
+
|
| 170 |
+
---
|
| 171 |
+
|
| 172 |
+
### Confusion Matrix between both Models:
|
| 173 |
+
|
| 174 |
+
| **Custom CNN** | **Xception** |
|
| 175 |
+
|------------|----------|
|
| 176 |
+
| <img src="https://files.catbox.moe/aulaxo.webp" width="100%"> | <img src="https://files.catbox.moe/gy6yno.webp" width="100%"> |
|
| 177 |
+
|
| 178 |
+
---
|
| 179 |
+
|
| 180 |
+
## Example Test Results (Custom CNN)
|
| 181 |
+
|
| 182 |
+
```
|
| 183 |
+
Test Accuracy: 87.89%
|
| 184 |
+
|
| 185 |
+
Macro Avg:
|
| 186 |
+
Precision: 0.8852
|
| 187 |
+
Recall: 0.8794
|
| 188 |
+
F1-Score: 0.8789
|
| 189 |
+
```
|
| 190 |
+
|
| 191 |
+
Despite solid metrics, performance dropped more noticeably on unseen real-world images compared to Xception.
|
| 192 |
+
|
| 193 |
+
---
|
| 194 |
+
|
| 195 |
+
## Deployment
|
| 196 |
+
|
| 197 |
+
### Run Locally
|
| 198 |
+
|
| 199 |
+
```bash
|
| 200 |
+
pip install -r requirements.txt
|
| 201 |
+
python app.py
|
| 202 |
+
```
|
| 203 |
+
|
| 204 |
+
Access at:
|
| 205 |
+
|
| 206 |
+
```
|
| 207 |
+
http://localhost:7860
|
| 208 |
+
```
|
| 209 |
+
|
| 210 |
+
---
|
| 211 |
+
|
| 212 |
+
## When to Use Each Approach
|
| 213 |
+
|
| 214 |
+
### Use Custom CNN if:
|
| 215 |
+
|
| 216 |
+
* Domain is highly specialized
|
| 217 |
+
* Pre-trained features don’t apply
|
| 218 |
+
* You need full architectural control
|
| 219 |
+
|
| 220 |
+
### Use Transfer Learning (e.g. DeiT or Xception) if:
|
| 221 |
+
|
| 222 |
+
* You want fast experimentation
|
| 223 |
+
* Efficiency matters
|
| 224 |
+
* You prefer high-level APIs
|
| 225 |
+
* You want best accuracy
|
| 226 |
+
* You care about generalization
|
| 227 |
+
* You need production-grade reliability
|
| 228 |
+
|
| 229 |
+
---
|
| 230 |
+
|
| 231 |
+
## Final Conclusion
|
| 232 |
+
|
| 233 |
+
On small or moderately sized datasets:
|
| 234 |
+
|
| 235 |
+
> Transfer learning isn’t an optimization - it’s a necessity.
|
| 236 |
+
|
| 237 |
+
Training from scratch forces the model to learn both general visual features and task-specific knowledge simultaneously.
|
| 238 |
+
|
| 239 |
+
Pre-trained models already understand edges, textures, and spatial structure.
|
| 240 |
+
Your dataset only needs to teach classification boundaries.
|
| 241 |
+
|
| 242 |
+
For most real-world tasks:
|
| 243 |
+
|
| 244 |
+
* Start with transfer learning
|
| 245 |
+
* Fine-tune carefully
|
| 246 |
+
* Only train from scratch if absolutely necessary
|
| 247 |
+
|
| 248 |
+
---
|
| 249 |
+
|
| 250 |
+
## Results
|
| 251 |
+
|
| 252 |
+
<p align="center">
|
| 253 |
+
<a href="https://files.catbox.moe/ss5ohr.mp4">
|
| 254 |
+
<img src="https://files.catbox.moe/3x5mp7.webp" width="400">
|
| 255 |
+
</a>
|
| 256 |
+
</p>
|