import asyncio
import os
from typing import Optional, Tuple
# Save original asyncio.run BEFORE any imports that might patch it (nest_asyncio)
_ORIGINAL_ASYNCIO_RUN = asyncio.run
# On ZeroGPU H200, TF32 matmul paths can occasionally trip cuBLAS errors in
# some einsum-heavy models. Prefer full FP32 math for stability.
os.environ.setdefault("NVIDIA_TF32_OVERRIDE", "0")
# ZeroGPU H200-specific workarounds for cuBLAS strided-batch GEMM issues
# H200 has 70GB VRAM, so memory isn't the issue - focus on CUDA context stability
# - Force synchronous CUDA execution to avoid race conditions during dynamic GPU allocation
# - Use deterministic cuBLAS workspace to ensure consistent behavior across GPU allocations
os.environ.setdefault("CUDA_LAUNCH_BLOCKING", "1")
os.environ.setdefault("CUBLAS_WORKSPACE_CONFIG", ":16:8")
import gradio as gr
import numpy as np
from PIL import Image, ImageDraw, ImageFont
# ZeroGPU decorator - only import on Hugging Face Spaces to avoid asyncio conflicts locally
def _make_spaces_fallback():
class _SpacesFallback:
@staticmethod
def GPU(*args, **kwargs):
def _decorator(fn):
return fn
return _decorator
return _SpacesFallback()
if os.environ.get("SPACE_ID"):
# Running on Hugging Face Spaces
try:
import spaces # type: ignore
except Exception:
spaces = _make_spaces_fallback() # type: ignore
else:
# Local development - skip spaces import to avoid asyncio conflicts
spaces = _make_spaces_fallback() # type: ignore
def _ensure_cache_dirs() -> None:
os.makedirs("outputs", exist_ok=True)
os.makedirs(os.path.join("outputs", "cache"), exist_ok=True)
os.environ.setdefault("EARTH2STUDIO_CACHE", os.path.join(os.getcwd(), "outputs", "cache"))
def _normalize_to_uint8(x: np.ndarray) -> np.ndarray:
x = np.asarray(x, dtype=np.float32)
finite = np.isfinite(x)
if not finite.any():
return np.zeros_like(x, dtype=np.uint8)
vmin = float(np.nanpercentile(x[finite], 2.0))
vmax = float(np.nanpercentile(x[finite], 98.0))
if vmax <= vmin:
return np.zeros_like(x, dtype=np.uint8)
y = (x - vmin) / (vmax - vmin)
y = np.clip(y, 0.0, 1.0)
return (y * 255.0).astype(np.uint8)
def _apply_simple_colormap(u8: np.ndarray) -> np.ndarray:
"""
Lightweight colormap without matplotlib:
map grayscale -> RGB using a simple blue->cyan->yellow->red ramp.
"""
u = u8.astype(np.float32) / 255.0
r = np.clip(1.5 * u, 0.0, 1.0)
g = np.clip(1.5 * (1.0 - np.abs(u - 0.5) * 2.0), 0.0, 1.0)
b = np.clip(1.5 * (1.0 - u), 0.0, 1.0)
rgb = np.stack([r, g, b], axis=-1)
return (rgb * 255.0).astype(np.uint8)
def _plot_latlon_field(lon: np.ndarray, lat: np.ndarray, field2d: np.ndarray, title: str) -> str:
"""
Save a quick image to outputs/ and return the file path.
Avoids matplotlib/cartopy to keep system deps minimal on Spaces.
"""
_ensure_cache_dirs()
out_path = os.path.join("outputs", "t2m.png")
gray = _normalize_to_uint8(field2d)
rgb = _apply_simple_colormap(gray)
img = Image.fromarray(rgb, mode="RGB").resize((1024, 512), resample=Image.BILINEAR)
draw = ImageDraw.Draw(img)
text = title
try:
font = ImageFont.load_default()
except Exception:
font = None
# simple text background for readability
pad = 6
tw, th = draw.textbbox((0, 0), text, font=font)[2:]
draw.rectangle((0, 0, tw + 2 * pad, th + 2 * pad), fill=(0, 0, 0))
draw.text((pad, pad), text, fill=(255, 255, 255), font=font)
img.save(out_path)
return out_path
def _gpu_duration(nsteps: int) -> int:
"""
Calculate GPU duration for inference only.
"""
nsteps = max(1, int(nsteps))
# 30s base (model to GPU) + 15s per step
return int(min(300, 30 + nsteps * 15))
@spaces.GPU(duration=lambda forecast_date, nsteps: _gpu_duration(int(nsteps)))
def _run_inference(forecast_date: str, nsteps: int):
"""
GPU-only function: load model, run inference, return extracted data.
ZeroGPU uses multiprocessing so we can't pass unpicklable objects (GFS, model).
Everything must be created inside this function.
"""
import torch
import earth2studio.run as run
from earth2studio.data import GFS
from earth2studio.io import ZarrBackend
_ensure_cache_dirs()
# Critical precision settings for ZeroGPU H200 cuBLAS stability
torch.backends.cudnn.benchmark = False
torch.set_float32_matmul_precision("highest") # Full FP32, no TF32
torch.backends.cuda.matmul.allow_tf32 = False
torch.backends.cudnn.allow_tf32 = False
torch.cuda.empty_cache()
# Force einsum operand contiguity to avoid cuBLAS strided-batch GEMM errors
_orig_einsum = torch.einsum
torch.einsum = lambda eq, *ops: _orig_einsum(
eq, *[op.contiguous() if torch.is_tensor(op) else op for op in ops]
) # type: ignore[assignment]
# Load model inside GPU function (ZeroGPU requirement)
from earth2studio.models.px import FCN
package = FCN.load_default_package()
model = FCN.load_model(package)
# Move to GPU with FP32 precision
device = torch.device("cuda")
model = model.float().to(device).eval()
torch.cuda.empty_cache()
# CRITICAL: Warmup CUDA/cuBLAS context on ZeroGPU's H200 before complex ops
# This ensures cuBLAS is fully initialized and strided-batch GEMM handlers are ready
try:
with torch.no_grad():
# Create dummy tensors matching FCN's expected input shape
# FCN expects (batch, channels, lat, lon) - use minimal batch/size for warmup
dummy_input = torch.randn(1, 73, 8, 8, device=device, dtype=torch.float32)
_ = model(dummy_input)
torch.cuda.synchronize()
torch.cuda.empty_cache()
except Exception as warmup_err:
# If warmup fails, log but continue - the actual inference might still work
print(f"[Warning] CUDA warmup failed: {warmup_err}")
data = GFS()
io = ZarrBackend()
try:
with torch.no_grad():
io = run.deterministic([forecast_date], nsteps, model, data, io, device=device)
# Extract ALL timesteps to numpy arrays (picklable) before returning
lon = np.asarray(io["lon"][:])
lat = np.asarray(io["lat"][:])
# Return all timesteps: shape (1, nsteps+1, lat, lon)
all_fields = np.asarray(io["t2m"][:])
return lon, lat, all_fields
finally:
# Cleanup: restore einsum and free GPU memory
torch.einsum = _orig_einsum # type: ignore[assignment]
del model, data, io
torch.cuda.empty_cache()
torch.cuda.synchronize()
def run_forecast(forecast_date: str, nsteps: int):
"""
Run Earth2Studio deterministic inference and return cached results.
Returns: (forecast_date, nsteps, lon, lat, all_fields, status_msg)
"""
_ensure_cache_dirs()
# Validate inputs
if not forecast_date:
return None, None, None, None, None, "ERROR: forecast_date is required (YYYY-MM-DD)."
nsteps = int(nsteps)
if nsteps < 1:
return None, None, None, None, None, "ERROR: nsteps must be >= 1"
# Run inference on GPU (model loaded inside due to ZeroGPU pickling)
try:
lon, lat, all_fields = _run_inference(forecast_date, nsteps)
except Exception as e:
return None, None, None, None, None, f"ERROR during inference: {type(e).__name__}: {e}"
# Return cached data for dynamic plot_step updates
status = f"SUCCESS: Computed {nsteps} forecast steps ({(nsteps+1)*6} hours total). Use plot_step slider to explore."
return forecast_date, nsteps, lon, lat, all_fields, status
def update_plot_from_cache(forecast_date, nsteps, lon, lat, all_fields, plot_step):
"""
Update the displayed plot from cached inference results (no GPU needed).
"""
if lon is None or lat is None or all_fields is None:
return None, "No cached results. Click 'Run Inference' first."
plot_step = int(plot_step)
nsteps = int(nsteps)
# Validate plot_step
if plot_step < 0 or plot_step > nsteps:
return None, f"Invalid plot_step {plot_step} (must be 0-{nsteps})"
# Extract the specific timestep
field = all_fields[0, plot_step]
# Plot
img_path = _plot_latlon_field(
lon,
lat,
field,
title=f"{forecast_date} - t2m - lead={6 * plot_step}h",
)
return img_path, f"Displaying step {plot_step} (lead time: {6 * plot_step} hours)"
def build_ui() -> gr.Blocks:
with gr.Blocks(title="Earth2Studio FCN (ZeroGPU)") as demo:
gr.Markdown(
"""
# Introduction to Earth2Studio
Earth2Studio is a Python package built to empower researchers, scientists, and enthusiasts in the fields of weather and climate science with the latest artificial intelligence models and capabilities. With an intuitive design and a comprehensive feature set, it serves as a robust toolkit for exploring modern AI workflows for weather and climate.
#### Learning Outcomes
- Earth2Studio key features
- How to instantiate a built-in prognostic model
- Creating a data source and IO object
- Running a simple built-in workflow
- Post-processing results
---
## Package Design
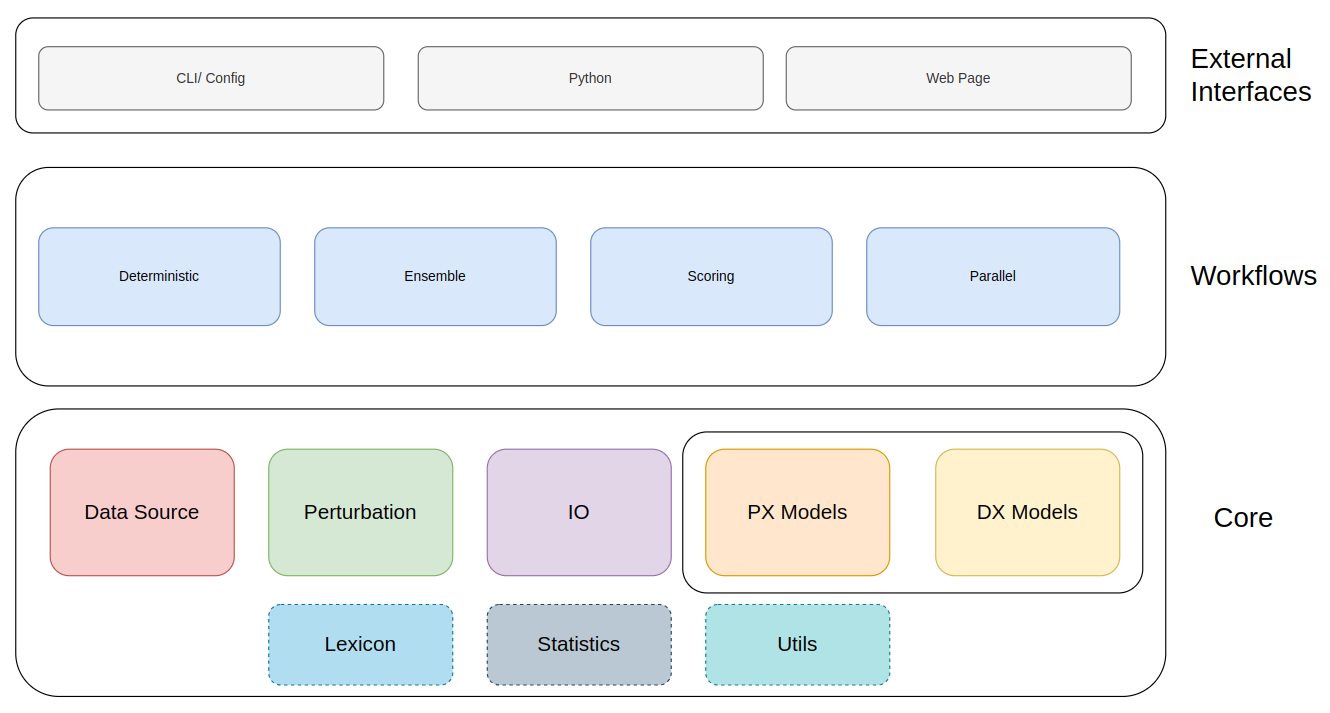
The goal of Earth2Studio is to enable users to extrapolate and build beyond what is implemented in it. The design philosophy embodies a **modular architecture** where the inference workflow acts as a flexible adhesive, seamlessly binding together various specialized software components with well-defined interfaces.
Model architecture overview.
By viewing the inference workflow as a dynamic connector, Earth2Studio facilitates effortless integration of these components, allowing researchers to easily swap out or augment functionalities to suit their specific needs.
### Key Features
- **Built-in Workflows**: Multiple built-in inference workflows to accelerate your development and research.
- **Prognostic Models**: Support for the latest AI weather forecast models offered under a coherent interface.
- **Diagnostic Models**: Diagnostic models for mapping to other quantities of interest.
- **Datasources**: Datasources to connect on-prem and remote data stores to inference workflows.
- **IO**: Simple, yet powerful IO utilities to export data for post-processing.
- **Statistical Operators**: Statistical methods to fuse directly into your inference workflow for more complex uncertainty analysis.
---
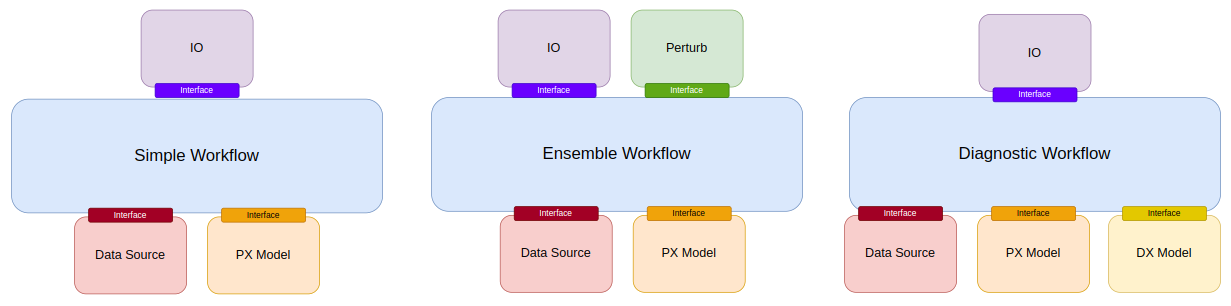
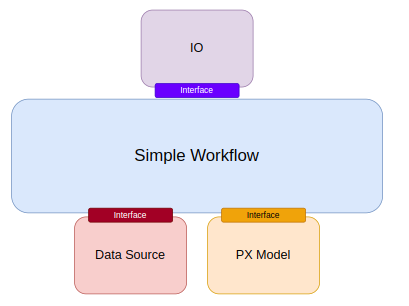
## Simple Deterministic Inference
All workflows inside Earth2Studio require constructed components to be handed to them. In this example, we use `earth2studio.run.deterministic`.
### Prognostic Models
Prognostic models are a class of models that perform time-integration. They are typically used to generate forecast predictions. Examples include:
| Model | Description |
|-------|-------------|
| `models.px.FCN` | FourCastNet - AFNO-based global weather forecasting model (used in this demo) |
| `models.px.SFNO` | Spherical Fourier Operator Network global prognostic model |
| `models.px.Pangu24` | Pangu Weather 24 hour model |
| `models.px.FuXi` | FuXi weather model with three auto-regressive U-net transformer models |
| `models.px.Aurora` | Aurora transformer-based weather model |
### Data Sources
Data sources are used for downloading, caching and reading different weather/climate data APIs into Xarray data arrays. Used for fetching initial conditions for inference and validation data for scoring:
| Data Source | Description |
|-------------|-------------|
| `data.GFS` | Global Forecast System initial state data source (used in this demo) |
| `data.ARCO` | Analysis-Ready, Cloud Optimized ERA5 re-analysis data curated by Google |
| `data.CDS` | Climate Data Store serving ERA5 re-analysis data |
| `data.HRRR` | High-Resolution Rapid Refresh North-American weather forecast model |
| `data.IFS` | Integrated Forecast System initial state data source |
### IO Backends
IO Backends are used for saving the inference results for further post-processing:
| IO Backend | Description |
|------------|-------------|
| `io.ZarrBackend` | Zarr format backend (used in this demo) |
| `io.NetCDF4Backend` | NetCDF4 format backend |
| `io.XarrayBackend` | Xarray backed IO object |
| `io.KVBackend` | Key-value (dict) backend |
---
## Code Overview
### Set Up
```python
import os
from earth2studio.data import GFS
from earth2studio.io import ZarrBackend
from earth2studio.models.px import FCN
# Set cache directory
os.environ['EARTH2STUDIO_CACHE'] = os.getcwd() + "/outputs/cache"
# Prognostic Model - Load from NGC (ngc://models/nvidia/modulus/modulus_fcn@v0.2)
package = FCN.load_default_package()
model = FCN.load_model(package)
# Data Source - Create the data source
data = GFS()
# IO Backend - Create the IO handler
io = ZarrBackend()
```
### Execute the Workflow
The `run.deterministic` function signature:
```python
def deterministic(
time: list[str] | list[datetime] | list[np.datetime64],
nsteps: int,
prognostic: PrognosticModel,
data: DataSource,
io: IOBackend,
output_coords: CoordSystem = OrderedDict({}),
device: torch.device | None = None,
) -> IOBackend:
\"\"\"Built in deterministic workflow.
This workflow creates a deterministic inference pipeline to produce
a forecast prediction using a prognostic model.
Parameters
----------
time : list[str] | list[datetime] | list[np.datetime64]
List of string, datetimes or np.datetime64
nsteps : int
Number of forecast steps
prognostic : PrognosticModel
Prognostic model
data : DataSource
Data source
io : IOBackend
IO object
output_coords: CoordSystem, optional
IO output coordinate system override
device : torch.device, optional
Device to run inference on
Returns
-------
IOBackend
Output IO object
\"\"\"
```
Running the forecast (each step is 6 hours for FCN, ~5-10 seconds/step on GPU):
```python
import earth2studio.run as run
nsteps = 4 # 4 steps = 24 hours
io = run.deterministic(["2024-01-01"], nsteps, model, data, io)
print(io.root.tree())
```
### Post Processing
```python
import matplotlib.pyplot as plt
import cartopy.crs as ccrs
forecast = "2024-01-01"
variable = "t2m"
step = 1 # lead time = 1 x 6 = 6 hrs
projection = ccrs.Robinson()
fig, ax = plt.subplots(subplot_kw={"projection": projection}, figsize=(10, 6))
im = ax.pcolormesh(
io["lon"][:],
io["lat"][:],
io[variable][0, step],
transform=ccrs.PlateCarree(),
cmap="Spectral_r",
)
ax.set_title(f"{forecast} - Lead time: {6*step}hrs")
ax.coastlines()
ax.gridlines()
plt.savefig("outputs/t2m_prediction.jpg")
```
---
## Interactive Demo
This Space runs the deterministic workflow using **FCN** (FourCastNet, checkpoint from [NVIDIA NGC](https://catalog.ngc.nvidia.com/orgs/nvidia/teams/modulus/models/modulus_fcn)) and plots **t2m** (2-meter temperature) at your chosen lead time.
FCN uses the AFNO (Adaptive Fourier Neural Operator) architecture and requires ~8GB VRAM.
"""
)
with gr.Row():
with gr.Column(scale=1):
forecast_date = gr.Textbox(
label="Forecast Date",
value="2024-01-01",
placeholder="YYYY-MM-DD",
info="GFS data available from ~2020-present",
max_lines=1,
)
with gr.Column(scale=1):
nsteps = gr.Slider(
minimum=1,
maximum=5,
step=1,
value=5,
label="Number of Forecast Steps",
info="Each step = 6 hours (5 steps = 30 hours total)",
)
run_btn = gr.Button("Run Inference on ZeroGPU H200", variant="primary")
with gr.Row():
plot_step = gr.Slider(
minimum=0,
maximum=5,
step=1,
value=2,
label="Display Timestep",
info="0=initial conditions, 1-N=forecast steps (updates instantly from cache)",
)
status = gr.Textbox(label="Status", interactive=False)
out_img = gr.Image(label="2-meter Temperature (t2m)", type="filepath")
# Hidden state to cache inference results
cached_date = gr.State(value=None)
cached_nsteps = gr.State(value=None)
cached_lon = gr.State(value=None)
cached_lat = gr.State(value=None)
cached_fields = gr.State(value=None)
def _sync_plot_step_max(n: int):
n = int(n)
# deterministic outputs n+1 time points, so max plot_step = n
new_max = max(1, n)
# Default to middle timestep for more interesting view
new_val = min(n // 2, new_max)
return gr.Slider(maximum=new_max, value=new_val)
# Update plot_step max when nsteps changes
nsteps.change(fn=_sync_plot_step_max, inputs=[nsteps], outputs=[plot_step])
# Run inference and cache results
run_btn.click(
fn=run_forecast,
inputs=[forecast_date, nsteps],
outputs=[cached_date, cached_nsteps, cached_lon, cached_lat, cached_fields, status],
).then(
fn=update_plot_from_cache,
inputs=[cached_date, cached_nsteps, cached_lon, cached_lat, cached_fields, plot_step],
outputs=[out_img, status],
)
# Update plot when plot_step slider changes (instant, uses cache)
plot_step.change(
fn=update_plot_from_cache,
inputs=[cached_date, cached_nsteps, cached_lon, cached_lat, cached_fields, plot_step],
outputs=[out_img, status],
)
return demo
# ============================================================
# STARTUP
# Note: Model is loaded inside @spaces.GPU function because
# ZeroGPU uses multiprocessing and can't pickle the model.
# ============================================================
print("[App] Building Gradio UI...")
# Create demo at module level so HF Spaces can find it
demo = build_ui()
if __name__ == "__main__":
# Fix for local testing: nest_asyncio patches asyncio.run in a way
# incompatible with uvicorn's loop_factory. Restore original.
asyncio.run = _ORIGINAL_ASYNCIO_RUN
demo.launch()