

library_name: transformers
license: cc-by-nc-4.0
pipeline_tag: text-generation
tags:
- text-to-sql
- reinforcement-learning
SLM-SQL: An Exploration of Small Language Models for Text-to-SQL
Important Links
📖Arxiv Paper | \ud83d\udcbbGitHub Repository | 🤗HuggingFace | 🤖ModelScope |
News
July 31, 2025: Upload model to modelscope and huggingface.July 30, 2025: Publish the paper to arxiv
Introduction
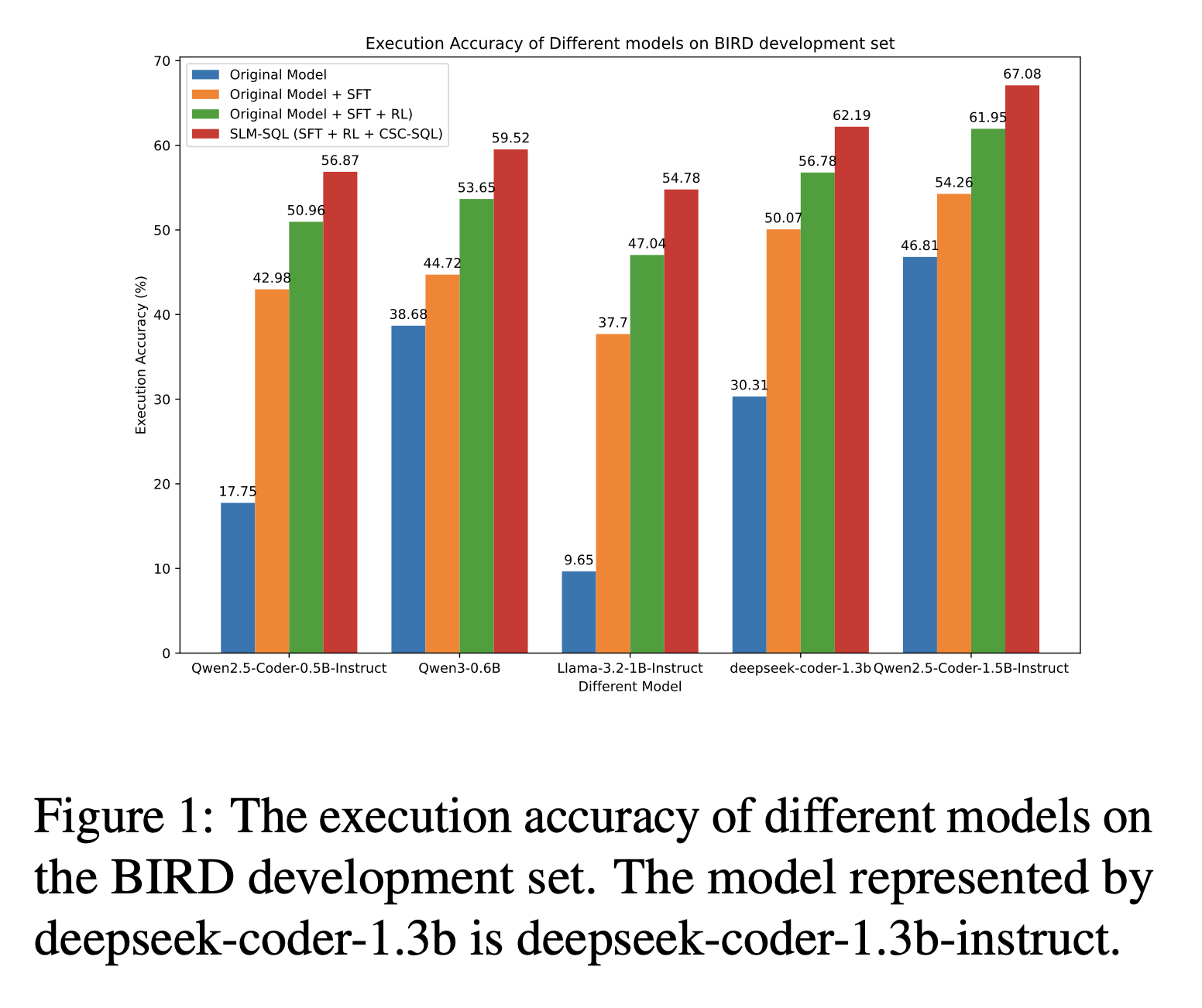
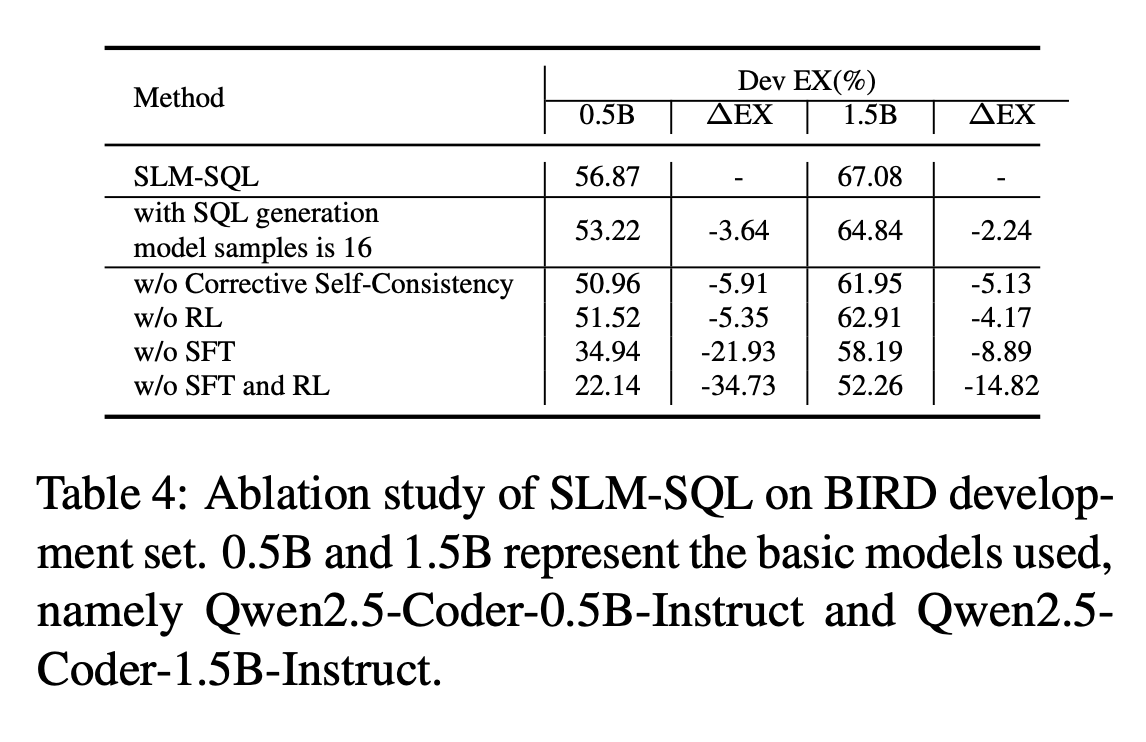
Large language models (LLMs) have demonstrated strong performance in translating natural language questions into SQL queries (Text-to-SQL). In contrast, small language models (SLMs) ranging from 0.5B to 1.5B parameters currently underperform on Text-to-SQL tasks due to their limited logical reasoning capabilities. However, SLMs offer inherent advantages in inference speed and suitability for edge deployment. To explore their potential in Text-to-SQL applications, we leverage recent advancements in post-training techniques. Specifically, we used the open-source SynSQL-2.5M dataset to construct two derived datasets: SynSQL-Think-916K for SQL generation and SynSQL-Merge-Think-310K for SQL merge revision. We then applied supervised fine-tuning and reinforcement learning-based post-training to the SLM, followed by inference using a corrective self-consistency approach. Experimental results validate the effectiveness and generalizability of our method, SLM-SQL. On the BIRD development set, the five evaluated models achieved an average improvement of 31.4 points. Notably, the 0.5B model reached 56.87% execution accuracy (EX), while the 1.5B model achieved 67.08% EX. We will release our dataset, model, and code to github: https://github.com/CycloneBoy/slm_sql.
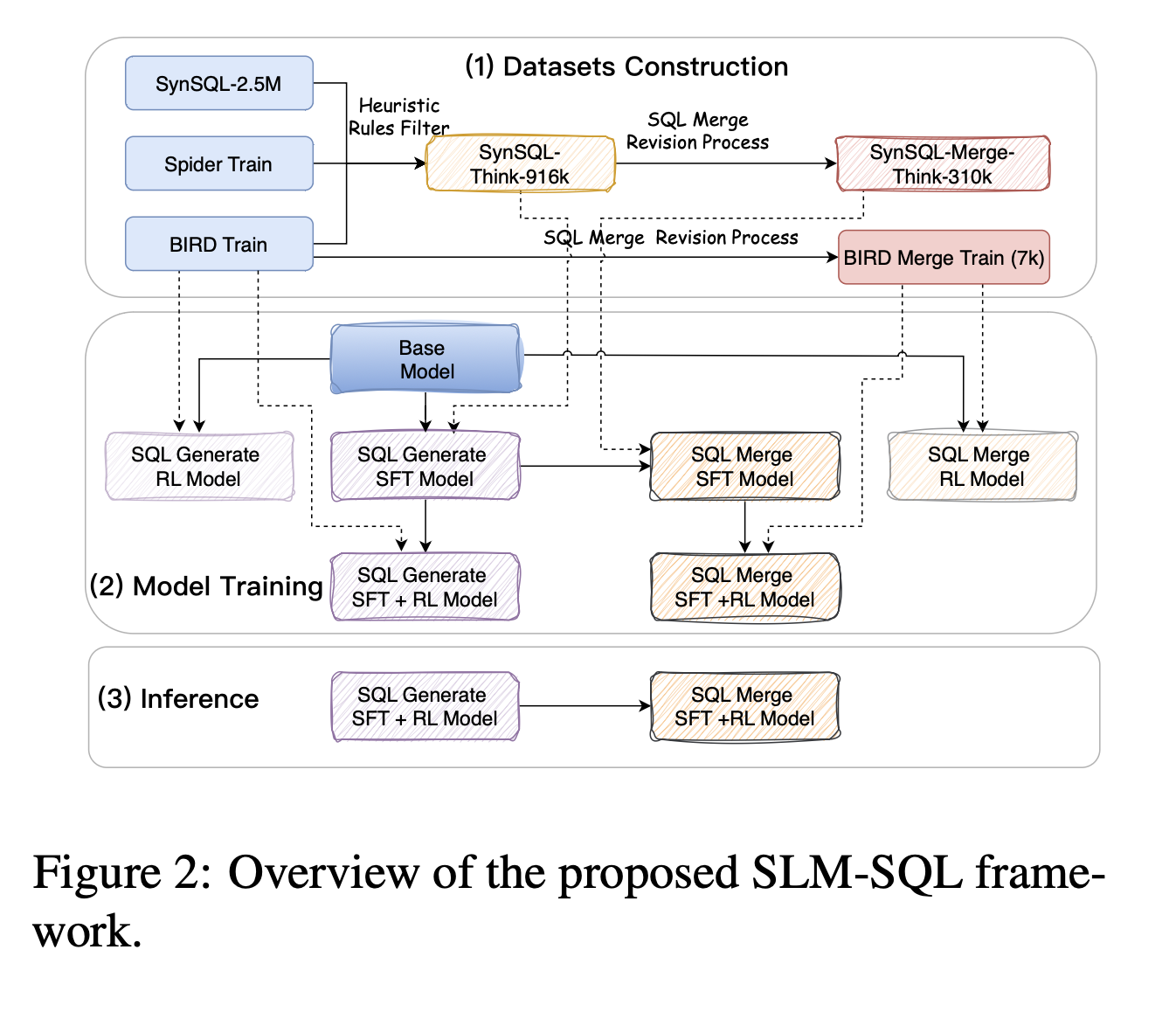
Framework
Main Results
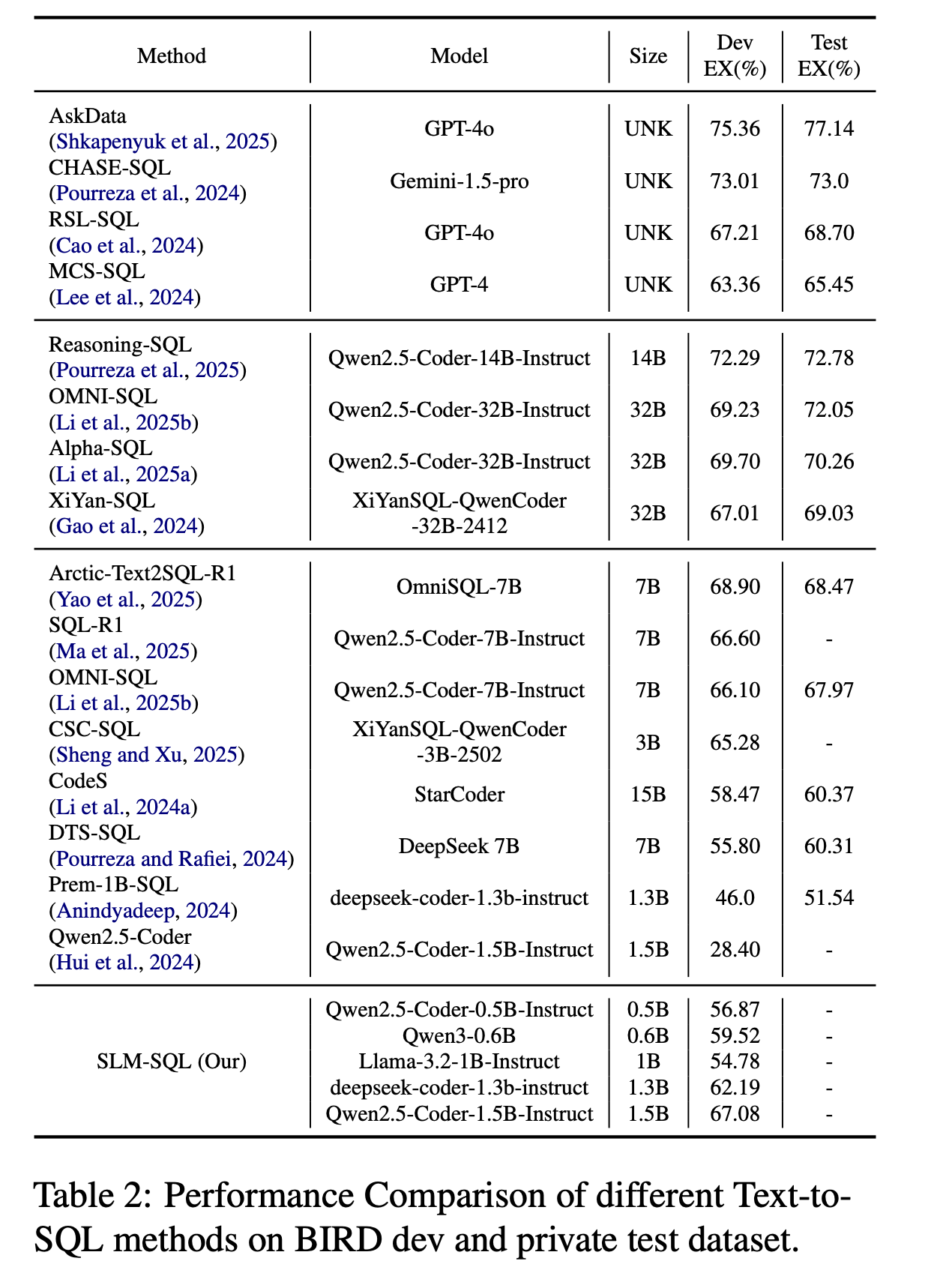
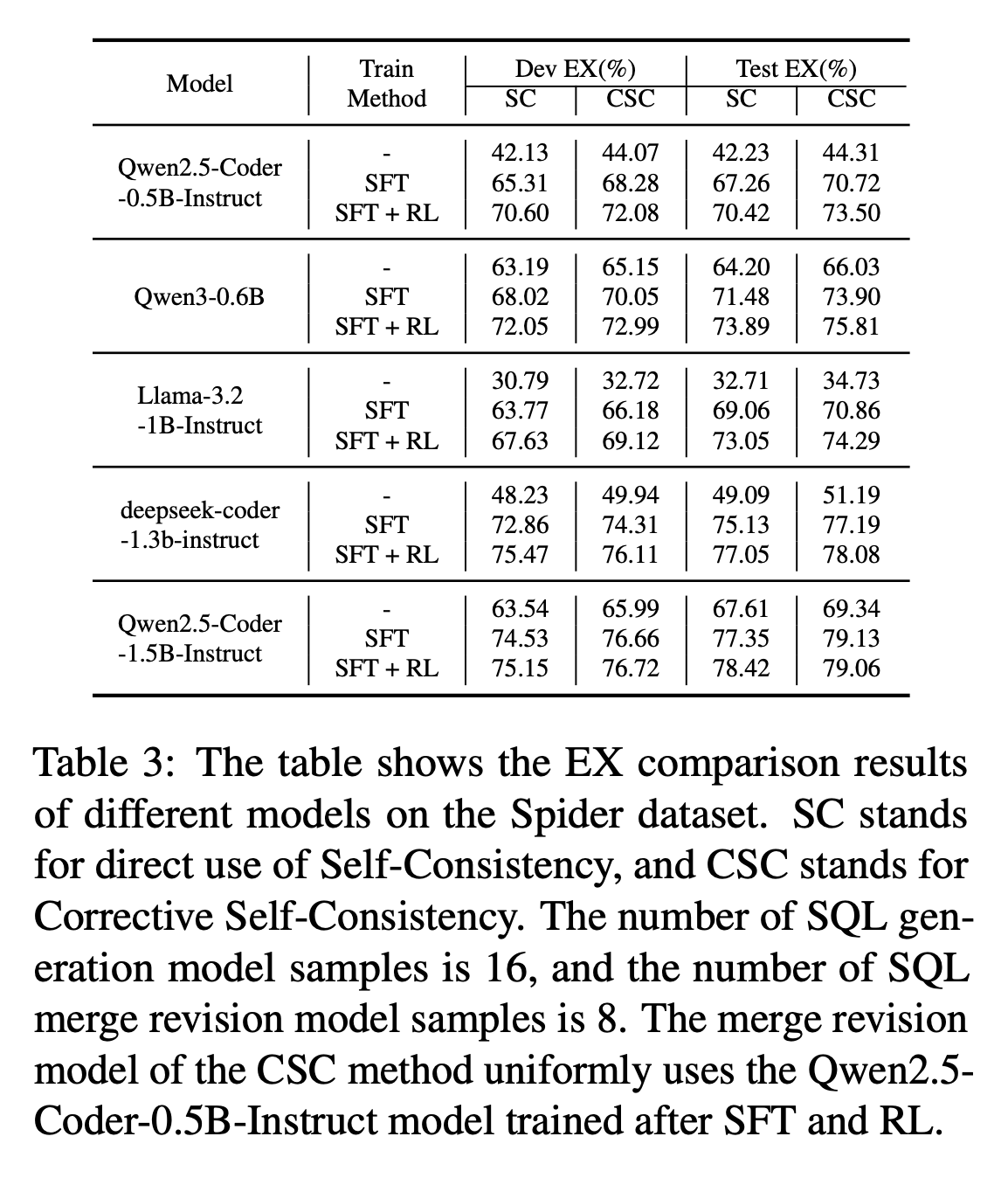
Performance Comparison of different Text-to-SQL methods on BIRD dev and test dataset.
Model
| Model | Base Model | Train Method | Modelscope | HuggingFace |
|---|---|---|---|---|
| SLM-SQL-Base-0.5B | Qwen2.5-Coder-0.5B-Instruct | SFT | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| SLM-SQL-0.5B | Qwen2.5-Coder-0.5B-Instruct | SFT + GRPO | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| CscSQL-Merge-Qwen2.5-Coder-0.5B-Instruct | Qwen2.5-Coder-0.5B-Instruct | SFT + GRPO | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| SLM-SQL-Base-1.5B | Qwen2.5-Coder-1.5B-Instruct | SFT | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| SLM-SQL-1.5B | Qwen2.5-Coder-1.5B-Instruct | SFT + GRPO | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| CscSQL-Merge-Qwen2.5-Coder-1.5B-Instruct | Qwen2.5-Coder-1.5B-Instruct | SFT + GRPO | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| SLM-SQL-Base-0.6B | Qwen3-0.6B | SFT | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| SLM-SQL-0.6B | Qwen3-0.6B | SFT + GRPO | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| SLM-SQL-Base-1.3B | deepseek-coder-1.3b-instruct | SFT | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| SLM-SQL-1.3B | deepseek-coder-1.3b-instruct | SFT + GRPO | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| SLM-SQL-Base-1B | Llama-3.2-1B-Instruct | SFT | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
Dataset
| Dataset | Modelscope | HuggingFace |
|---|---|---|
| SynsQL-Think-916k | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| SynsQL-Merge-Think-310k | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
| bird train and dev dataset | \ud83e\udd16 Modelscope | \ud83e\udd17 HuggingFace |
Sample Usage
You can easily load the model and tokenizer using the Hugging Face transformers library to perform text-to-SQL generation.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# Replace with the specific model you want to use, e.g., "cycloneboy/SLM-SQL-0.5B"
model_id = "cycloneboy/SLM-SQL-0.5B"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Adjust as needed (e.g., torch.float16 or remove for auto)
device_map="auto"
)
# Example natural language query for SQL generation
query = "Find the names of all employees who work in the 'Sales' department."
# Prepare the prompt using the model's chat template
chat_messages = [{"role": "user", "content": query}]
prompt = tokenizer.apply_chat_template(chat_messages, tokenize=False, add_generation_prompt=True)
# Generate the SQL query
model_inputs = tokenizer([prompt], return_tensors="pt").to(model.device)
generated_ids = model.generate(
model_inputs.input_ids,
max_new_tokens=256,
do_sample=True,
temperature=0.7,
top_p=0.9
)
# Decode and print the generated SQL
generated_text = tokenizer.batch_decode(generated_ids[:, model_inputs.input_ids.shape[1]:], skip_special_tokens=True)[0]
print(generated_text)
TODO
- Release inference code
- Upload Model
- Release training code
- Fix bug
- Update doc
Thanks to the following projects
Citation
@misc{sheng2025slmsqlexplorationsmalllanguage,
title={SLM-SQL: An Exploration of Small Language Models for Text-to-SQL},
author={Lei Sheng and Shuai-Shuai Xu},
year={2025},
eprint={2507.22478},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2507.22478},
}
@misc{sheng2025cscsqlcorrectiveselfconsistencytexttosql,
title={CSC-SQL: Corrective Self-Consistency in Text-to-SQL via Reinforcement Learning},
author={Lei Sheng and Shuai-Shuai Xu},
year={2025},
eprint={2505.13271},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2505.13271},
}